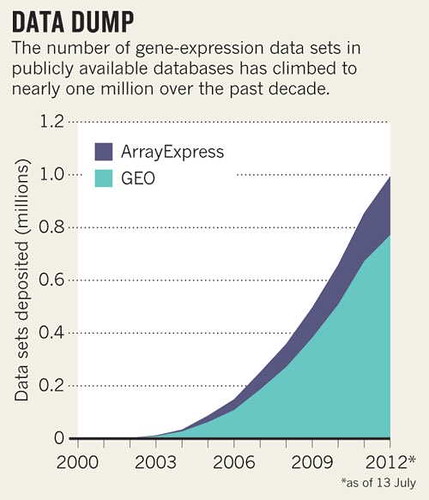
I was recently called out by one of my colleagues for saying that ontologies were boring, this despite my own doctoral work on knowledge representation. Motivating my glib comment was an image of a group of pasty-faced individuals gathered around a large boardroom table and discussing which angel fit on which pin. Events from this past weekend are a reminder why such glibness is not helpful.
The American Psychiatric Association has just approved a set of updates, revisions and changes to the reference manual (DSM5) used to diagnose mental disorders. Among the changes are those redefining the inclusion and exclusion criteria for autistic disorders. By changing which children are classified as having an autistic disorder, parents will be made to feel more or less comfortable having a child carrying the diagnosis. Just as importantly, insurance companies and school programs might shift their criteria that determine which child and family gets what kind of support and at what cost. In the near term, clinical trials for the treatment of autism may not include the same patients as they would have prior to this retaxonomization.
So, are ontologies boring? Perhaps. But they certainly belong to the class of hugely important societal constructs.
Hat tip: David Osterbur.